How-to Optimize Rust Programs on Linux
In the Finance industry, performance is serious business. These are people who want to use neutrino beams to transmit information through the Earth because fiber optics are too slow. Clearly, I have my work cut out for me making fix-rs fast. In this post I’m going to cover the process of optimizing a program or library written in Rust. I’ll cover actual optimizations in later posts. Since fix-rs is Linux only, I’ll be following a Linux specific workflow.
Without further ado, let’s start down the optimization rabbit hole.
The Process
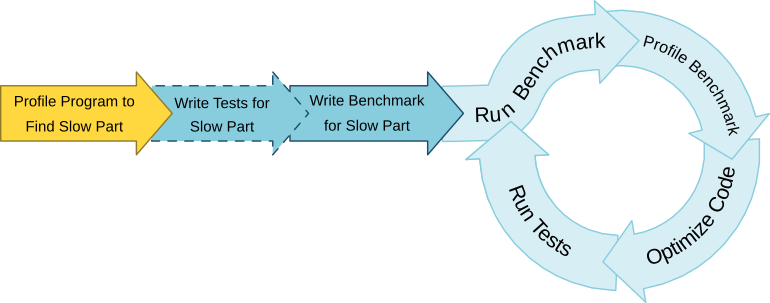
Optimization is the process of changing your code to run faster by doing less work or getting more work done over a period of time. You should start by running your program with a profiler. A profiler is a tool used to help you find where your program spends most of its time and why it takes so long. I’ll cover how to profile your code a little later.
Once you’ve found what parts of your program are slow, it’s time to dive in and modify some code, right? Wrong! You should strongly consider writing tests first. Yes, writing tests is boring but hear me out. It’s very common to break your code while optimizing. Tests help you detect these breaks immediately. Without tests, you could spend a lot of time making improvements that turn out to be wrong. Then all of that time will have been wasted.
To make the optimization process faster, create a benchmark for the section of code or set of data you’re optimizing for. Benchmarks measure how long it takes your code to run. The benchmark system built into Rust is nice because you don’t have to manually insert timers every time you want to measure performance. Which, you’ll want to do often as your project grows so everything keeps running fast. Rust Nightly is required but take advantage if you can because it’ll absolutely make your work easier.
If it isn’t practical for you to use Rust’s benchmark system, you might be able to benchmark your program using the shell1. You won’t have the nanosecond resolution you do with the above method though.
$ cargo build --release
Finished release [optimized + debuginfo] target(s) in 86.85 secs
$ seq 10 | xargs -Iz \time target/release/<program-name>
1.82user 1.32system 0:03.25elapsed 96%CPU (0avgtext+0avgdata 32764maxresident)k
0inputs+0outputs (0major+1557471minor)pagefaults 0swaps
1.90user 1.50system 0:03.46elapsed 98%CPU (0avgtext+0avgdata 32180maxresident)k
0inputs+0outputs (0major+1557367minor)pagefaults 0swaps
...
1.94user 1.45system 0:03.45elapsed 98%CPU (0avgtext+0avgdata 32948maxresident)k
0inputs+0outputs (0major+1557491minor)pagefaults 0swaps
Now you can start the optimization loop:
- Benchmark: Measure how long the work you’re looking to improve takes. Use a Rust benchmark or another method with consistent timing.
- Profile: Run your benchmark through a profiler to find out which parts of your code take the longest to run. This is different from your original profiling run because it focuses on just the section you’re benchmarking. The result is easier to examine and it’s completely based off your most recent attempt at optimization.
- Optimize: Use the results of your profiling to make changes to your code. Change algorithms, re-arrange data, use multiple threads, drop down to assembly, experiment.
- Test: Run your tests to make sure your code functions the same. A great benchmark time is worthless if the code doesn’t do what you want.
Repeat this process until your code is fast enough. After each benchmark step, make a note of the time and what you changed. These notes let you see how much performance has improved as well as reason about when it’s time to move on.
Preparing to Profile
Except for profiling, most of the optimization process should be familiar if you’ve worked through the Rust Book. Before you profile your code, you need to make sure to compile in release mode and include debug information. Release mode is used when building an executable for distribute because it enables various compiler optimizations. This makes sure we don’t waste time optimizing what the compiler does automatically. Including the debug information lets us see the cost of running each line of our source code2. Depending on what we want to profile, there are three different approaches:
-
A rust source file without cargo: Use
rustc, add the-Oflag to create a release build, and add the-gflag for debug information.$ rustc -O -g main.rs -o <output-program-name> -
An executable built using Cargo: Edit your
Cargo.tomlfile and adddebug = trueunder the[profile.release]section. If the section doesn’t exist, add it. Then runcargo build --release. Make sure to setdebug = falsewhen building executables for distribution.# File: Cargo.toml [profile.release] debug = true -
A benchmark built using Cargo (Rust Nightly Required): Edit your
Cargo.tomlfile and adddebug = trueunder the[profile.bench]section. If the section doesn’t exist, add it. Then runcargo bench --no-run.# File: Cargo.toml [profile.bench] debug = true
Profiling
With that out of the way, we can now profile our code. Enter Valgrind, an amazing program with an assortment of tools. In our case, we want to use the Callgrind tool to profile our program. Although Valgrind is more commonly used with C and C++ programs, it works with Rust as well.
Profiling with Valgrind is done using the following command:
$ valgrind --tool=callgrind --dump-instr=yes --collect-jumps=yes --simulate-cache=yes <path-to-your-executable> [your-executable-program-options]
Where the flags are:
--tool=callgrind: Use the Callgrind tool. Valgrind includes a number of tools but Callgrind is all we need to profile.--dump-instr=yes: Include the executed assembly code in the output. It’s not necessary unless you plan to look at the assembly.--collect-jumps=yes: Include the where-to and how many times jumps occur. Usually for measuring conditional branches (eg.if <statement> { } else { }).--simulate-cache=yes: Include estimates of memory access with respect to the cache in your CPU. This is the same data that would be included if Valgrind is run with--tool=cachegrind. Using this flag in combination with--tool=callgrindgives us both the Callgrind and Cachegrind data in one run.
The path to your executable depends on how you compiled it. If you used rustc directly, then it’s at the path specified with the -o option. If you didn’t use the -o option, then it’s in the current directory and has the same name as the source file but without the .rs extension.
For executables compiled with the cargo build --release command, check the target/release/ directory. The default executable will have the same name as the package name listed in Cargo.toml. Executables compiled from the src/bin/ directory are also found here.
Finding the right executable created with the cargo bench command can be a little tricker when you have a bunch of benchmarks. The easiest way is to run the cargo bench command and find the “Running target/release/deps/…” line above the benchmark you want to profile. For example, if I run cargo bench on fix-rs, I get the following:
$ cargo bench
Finished release [optimized + debuginfo] target(s) in 0.0 secs
Running target/release/deps/fix_rs-dab0b33459478e51
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
Running target/release/deps/fix_rs-048321f1b5403f05
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
Running target/release/deps/lib-8403c8edede1de55
running 2 tests
test parse_simple_message_bench ... bench: 11,621 ns/iter (+/- 183)
test serialize_simple_message_bench ... bench: 3,855 ns/iter (+/- 225)
test result: ok. 0 passed; 0 failed; 0 ignored; 2 measured
I can see from above that there are currently only two benchmarks and both use the lib-8403c8edede1de55 executable. I also need to include the --bench <name of bench> flag to make sure I’m only profiling one benchmark. To profile the parse_simple_message_bench benchmark, I would use Valgrind as follows:
$ valgrind --tool=callgrind --dump-instr=yes --collect-jumps=yes --simulate-cache=yes target/release/lib-8403c8edede1de55 --bench parse_simple_message_bench
==3671== Callgrind, a call-graph generating cache profiler
==3671== Copyright (C) 2002-2015, and GNU GPL'd, by Josef Weidendorfer et al.
==3671== Using Valgrind-3.12.0 and LibVEX; rerun with -h for copyright info
==3671== Command: target/release/lib-8403c8edede1de55 --bench parse_simple_message_bench
==3671==
--3671-- warning: L3 cache found, using its data for the LL simulation.
==3671== For interactive control, run 'callgrind_control -h'.
running 1 test
test parse_simple_message_bench ... bench: 1,770,323 ns/iter (+/- 30,844)
test result: ok. 0 passed; 0 failed; 0 ignored; 1 measured
==3671==
==3671== Events : Ir Dr Dw I1mr D1mr D1mw ILmr DLmr DLmw
==3671== Collected : 237433877 49273237 39407087 1539315 78879 121110 4266 3049 3764
==3671==
==3671== I refs: 237,433,877
==3671== I1 misses: 1,539,315
==3671== LLi misses: 4,266
==3671== I1 miss rate: 0.65%
==3671== LLi miss rate: 0.00%
==3671==
==3671== D refs: 88,680,324 (49,273,237 rd + 39,407,087 wr)
==3671== D1 misses: 199,989 ( 78,879 rd + 121,110 wr)
==3671== LLd misses: 6,813 ( 3,049 rd + 3,764 wr)
==3671== D1 miss rate: 0.2% ( 0.2% + 0.3% )
==3671== LLd miss rate: 0.0% ( 0.0% + 0.0% )
==3671==
==3671== LL refs: 1,739,304 ( 1,618,194 rd + 121,110 wr)
==3671== LL misses: 11,079 ( 7,315 rd + 3,764 wr)
==3671== LL miss rate: 0.0% ( 0.0% + 0.0% )
The profiler’s result is the callgrind.out.<pid> file placed in the current directory. The pid (process identifier) is the number listed between the double equal signs in Valgrind’s output. In the example above, the file is called callgrind.out.3671.
Tip
If you're profiling a program that's designed to never exit or is just taking too long, feel free to stop your program by pressing Ctrl+C in the terminal. Valgrind's Callgrind tool generates useful profiling information even if your program doesn't exit cleanly.
Examining Profiling Results
It’s possible to examine the profiler’s output using the command line but it’s far easier to use a GUI tool called KCachegrind. It’s available on all major Linux distributions through their respective package managers.
Open the callgrind.out.<pid> file with KCachegrind and you’ll see a window like below.
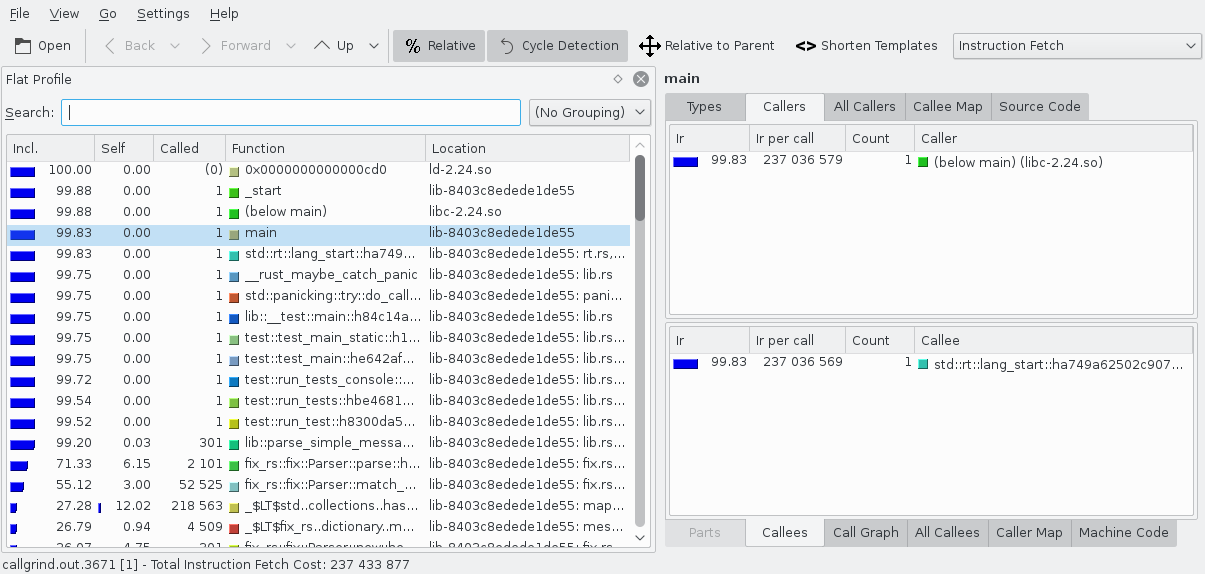
Before going any further, we need to go over the cost of running code. KCachegrind initially shows the Instruction Fetch which is the number of instructions executed. This is a good estimate for the amount of time spent. But there are other useful costs like L1 Instr. Fetch Miss which shows how many times the Level 1 instruction cache missed. Use the combo box on the toolbar in the top right to change the cost being shown.
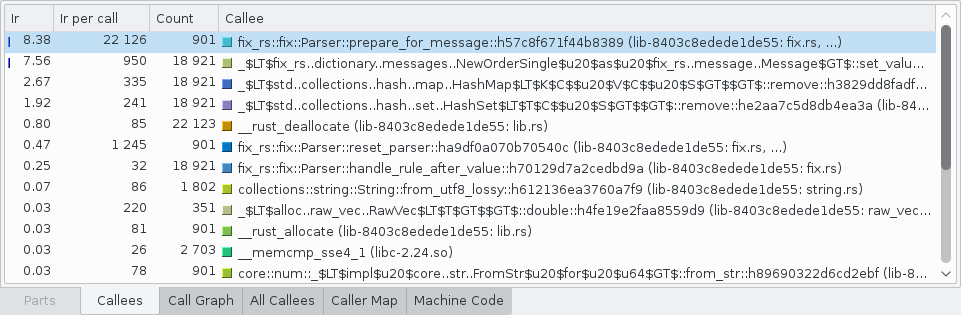
On the left is the Flat Profile area. It lists all of the functions that were run. The columns are:
- Incl.: The cost of running the code inside of this function, including calls to other functions.
- Self: The cost of running the code inside of this function, excluding calls to other functions.
- Called: How many times this function was called.
- Function: Name of function. Rust function names are mangled3 but KCachegrind does a reasonable job making them human readable.
- Location: The executable or shared library containing the function. A list of source files containing code used in the function’s body is appended when available.
Note that the listed costs are an accumulation and not an average or from a single call.
By default, the functions here are sorted by Incl. which means that outer most functions, like main(), are almost always going to be at the top. Sometimes you’ll want to sort the functions by just their own cost. To do so, click the Self column at the top.
Clicking a function in this list shows more information about it in various tabs on the right. Most of these tabs show related functions that you can double click to quickly jump around the call graph and find bottlenecks. The most important of these tabs are:
- Types: Lists the different costs for the selected function.

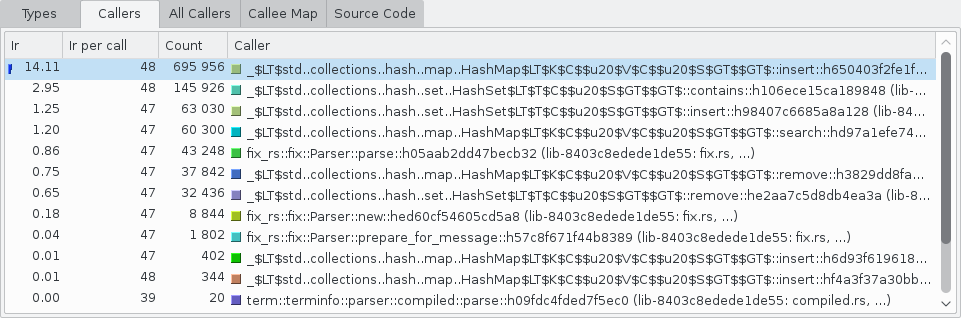
- Callers: Lists all of the functions that directly called the selected function.
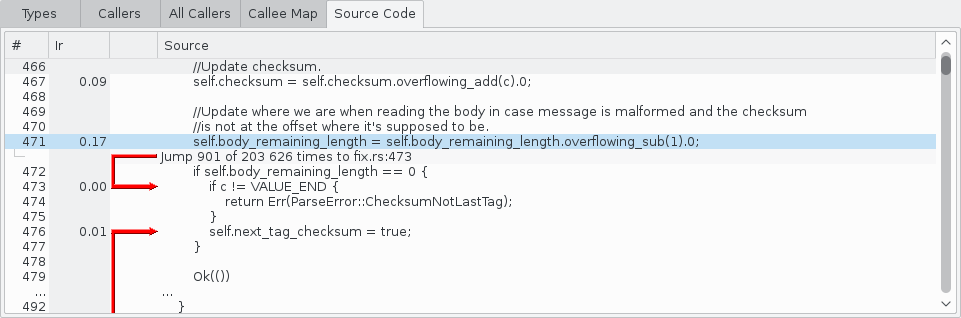
- Source Code: The source code of the selected function with each line annotated by cost. Keep in mind that some source lines may appear to be missing due to the compiler merging lines, inlining functions, or other optimizations.
- Callees: Lists all of the functions that the selected function calls.
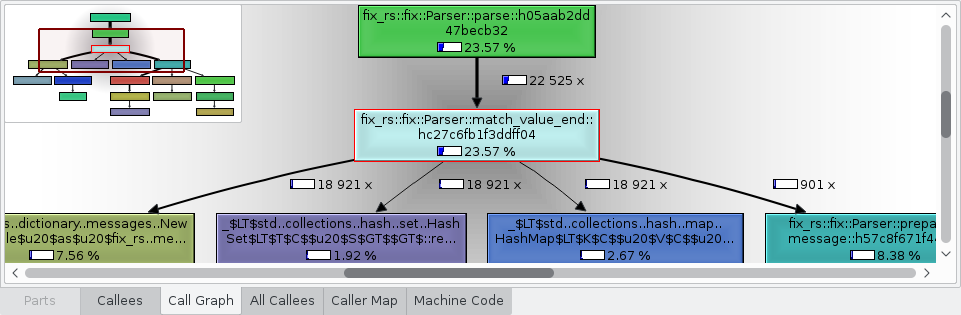
- Call Graph: A graph showing the callers and callees of the selected function.
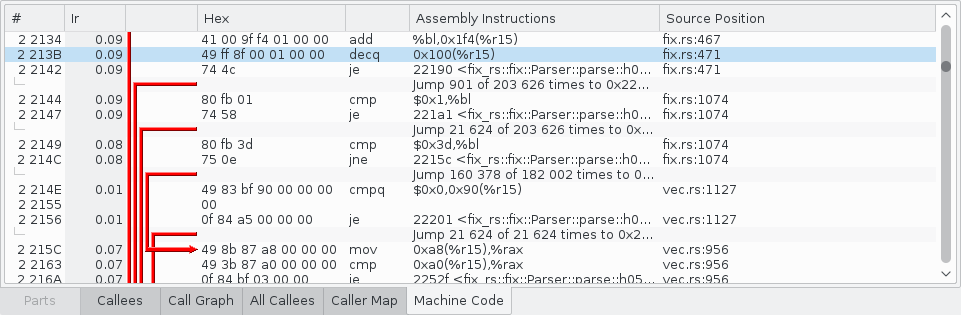
- Machine Code: The assembly code of the selected function with each instruction annotated by cost.
Conclusion
Optimization is an enthralling cycle that soaks up time. Remember to focus on the slowest parts of your code, work to make them fast enough, and then think hard about whether it’s time to move your attention elsewhere.
More About Optimization
- perf and OProfile can both do system-wide profiling which is useful when you’re optimizing around system calls.
- What Every Programmer Should Know About Memory by Ulrich Drepper [PDF] is an essential read when working on memory bottlenecked algorithms. In summary, the cache is king.
- Agner’s Optimization Manuals, particularly those on assembly, are fantastic when calculating performance across different CPU models.
- Profiling Rust applications on Linux Llogiq covered this topic awhile ago. In particular, he covers reviewing Valgrind’s output using the command line and how to profile with OProfile.
Footnotes
-
The following example runs the program multiple times for a better estimate of the minimal run-time. If one run takes a minute or more, then you probably don’t need the minimum in order to measure an improvement. ↩
-
Some lines will actually be missing because the compiler optimizes them out. ↩
-
You can turn off name mangling with the
#[no_mangle]function attribute. See symbol_names.rs for an explanation on how Rust mangles names. ↩